SituatedQA: Incorporating Extra-Linguistic Contexts into QA
About
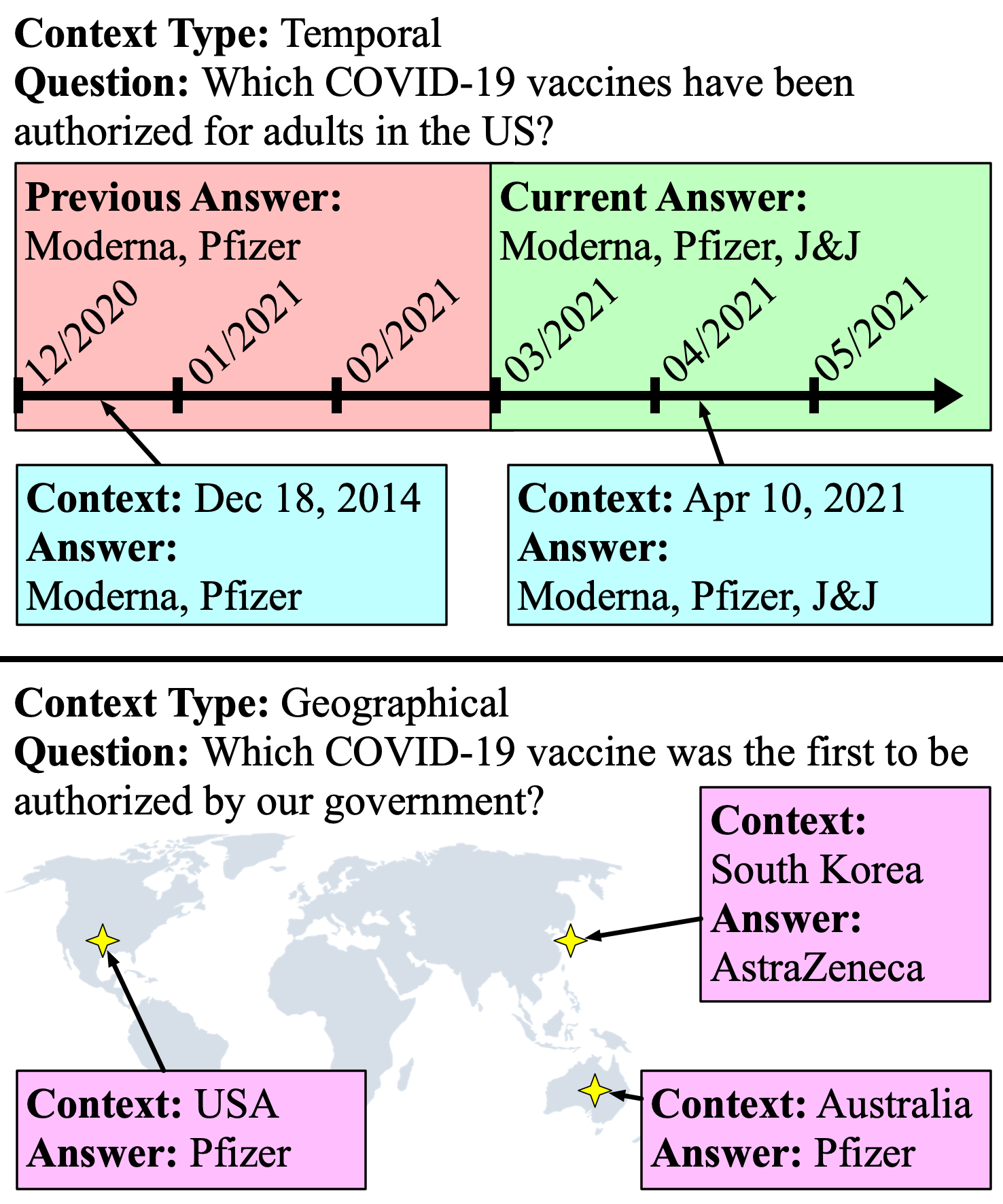
Answers to the same question may change depending on the extra-linguistic contexts (when and where the question was asked). To study this challenge, we introduce SituatedQA, an open-retrieval QA dataset where systems must produce the correct answer to a question given the temporal or geographical context. To construct SituatedQA we first identify such questions in existing QA datasets. We find that a significant proportion of information seeking questions have context-dependent answers (e.g., roughly 16.5% of NQ-Open). For such context-dependent questions, we then crowdsource alternative contexts and their corresponding answers. Our study shows that existing models struggle with producing answers that are frequently updated or from uncommon locations. We further quantify how existing models, which are trained on data collected in the past, fail to generalize to answering questions asked in the present, even when provided with an updated evidence corpus (a roughly 15 point drop in accuracy). Our analysis suggests that open-retrieval QA benchmarks should incorporate extra-linguistic context to stay relevant globally and in the future.
Citations
If you find our work helpful, please cite us.
@article{ zhang2021situatedqa,
title={ {S}ituated{QA}: Incorporating Extra-Linguistic Contexts into {QA} },
author={ Zhang, Michael J.Q. and Choi, Eunsol },
journal={ Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) },
year={ 2021 }
}
Please also credit the creators of the datasets we built ours off of: NaturalQuestions, WebQuestions, TyDi-QA, and MS MARCO.
@article{ kwiatkowski2019natural,
title={ Natural questions: a benchmark for question answering research},
author={ Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and others },
journal={ Transactions of the Association for Computational Linguistics (TACL) },
year={ 2019 }
}
@article{clark-etal-2020-tydi,
title = "{T}y{D}i {QA}: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages",
author = { Clark, Jonathan H. and Choi, Eunsol and Collins, Michael and Garrette, Dan and Kwiatkowski, Tom and Nikolaev, Vitaly and Palomaki, Jennimaria },
journal = { Transactions of the Association for Computational Linguistics (TACL) },
year = { 2020 },
}
@inproceedings{Berant2013SemanticPO,
title={ Semantic Parsing on Freebase from Question-Answer Pairs },
author={ Jonathan Berant and Andrew K. Chou and Roy Frostig and Percy Liang },
booktitle={ Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) },
year={2013}
}
@article{Campos2016MSMA,
title={MS MARCO: A Human Generated MAchine Reading COmprehension Dataset},
author={Daniel Fernando Campos and Tri Nguyen and M. Rosenberg and Xia Song and Jianfeng Gao and Saurabh Tiwary and Rangan Majumder and L. Deng and Bhaskar Mitra},
journal={ArXiv},
year={2016},
volume={abs/1611.09268}
}
Contact
For any questions, please contact Michael Zhang or open a github issue.